eBPF学习笔记5
未完待续……
参考链接 libbpf HOWTO: BCC to libbpf conversion
上一篇文章记录了如何使用bpftrace来编写bpf程序,这篇就来说说如何使用BCC(BPF Compiler Collection)。正如前一篇笔记说的,bpftrace简单是简单,但是对于某些复杂场景功能还略有不足。比如,很多的Linux工具都支持各种各样的参数,这时bpftrace就不能满足需求了。
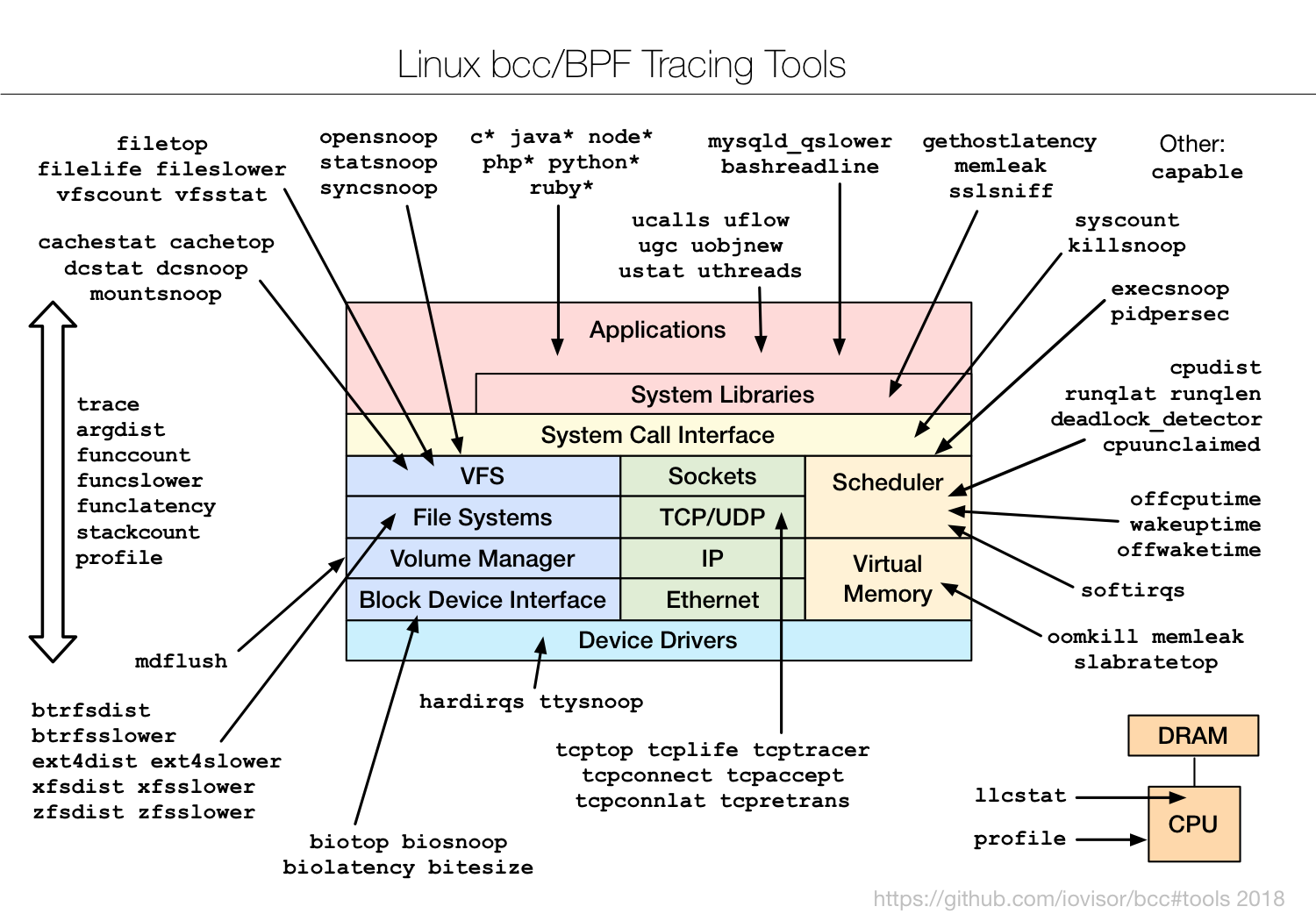
如图所示,BCC已经提供了大量的二进制工具可以直接使用,这篇笔记主要侧重于如何使用BCC编写eBPF程序。
这篇文章主要来说说bpftrace,这个语法十分的简单而且功能还在不停的完善中,后续变化一定以官网文档为准。
bpftrace程序由3个部分组成:
探针probes /过滤器filters/ {动作actions}
既可以把程序保存为.bt文件后(建议而不强制)使用btftrace xxx.bt来执行,也可以通过单行指令bpftrace -e 'probes /filters/ { actions }'来执行。
其中,过滤器部分可以省略掉,不省略的话只有符合过滤器条件时才会执行动作。
支持?::三元操作符、if{...}else{...}语句、unroll (count) {statements}这种有界的循环、while (condition) {...}(5.3+内核版本添加的实验性支持)、[]数组、(,)元组、以及C语言中的常见运算符。
上一篇笔记里说编写运行BPF程序推荐2种方法:bpftrace和BCC,按照惯例来个hello world。
之前说过很多功能都是新版内核才支持,想使用CO-RE内核需要开启CONFIG_DEBUG_INFO_BTF=y和CONFIG_DEBUG_INFO=y 这两个编译选项,所以建议使用最新的发行版,比如:
按照惯例,第一篇先来个概览,做一些基础知识的铺垫。
目前这个技术领域还相对较“新”,本人也刚刚开始摸索学习,有错误的地方还请大佬们多多指正。
eBPF由BPF(Berkeley Packet Filter)扩展而来,提供了一种在内核事件和用户程序事件发生时安全注入代码的机制,使得非内核开发人员也可以对内核进行控制,无需修改内核源码和重新编译内核就可以扩展内核的功能。(简单类比的话,就类似未成年人可以在有限的范围内安全的做一些成年人才能做的事了)
之前想对内核做点什么,需要编写内核模块后编译进去,一个不小心就把内核搞崩了。而eBPF则通过即时编译器(JIT),保证只有经过验证的、安全的eBFP指令才会被内核执行。
从业界的角度看,最主要的因素还是对性能的追求。比如,小规模的k8s使用iptables就可以搞定容器网络通信,但随着规模的增大iptables性能问题越发明显,然后就有了IPVS模式。虽然IPVS和iptables都是基于Netfilter,但由于IPVS使用哈希表而iptables使用规则链表,导致前者的性能高于后者。然后随着集群规模的再次扩大,对性能有了更高的要求,于是乎eBPF就成了目前进一步提高性能的技术方案:
The aforementioned KubeCon Talk performed specific measurements on iptables as a bottleneck for Kubernetes service forwarding and noted that throughput degraded by ~30% with 5,000 services deployed, and by 80% with 10,000 services (a 6X performance difference). Likewise, rule updates at 5,000 services took 11 minutes, ages in a world of continuous delivery.
Thanks to the flexibility of BPF, Cilium performs this same operation with O(1) average runtime behavior using a simple BPF map based hash table, meaning the lookup latency at 10,000 or even 20,000 services is constant. Likewise, updates to these BPF maps from userspace are highly-efficient, meaning that even with 20,000+ services, the time to update a forwarding rule is microseconds, not hours.
For these reasons, Facebook has recently presented their use of BPF and XDP for load-balancing in a public talk to replace IPVS after measuring an almost 10x performance increase.